AWS S3 In Plain English Simple Storage Service
So, it's officially called Simple Storage Service and we jokingly refer to it as the Amazon Unlimited Internet File Server, but it's actully much better than that.
What Does S3 Do?
It’s the place you put your files as a first step to doing something interesting with them. If you’re coming from a traditional web hosting background, it’s similar to how you’d FTP or SSH your files from your development.
It stores the images and other assets for websites, keeps backup and shares files between services, and hosts static websites. Also, many of the other AWS services write and read from S3.
- It’s a very safe, stable place to keep your files. You don’t have to worry about your server’s hard drive crashing and files being lost.
- It won’t crash no matter how much traffic gets thrown at it - Amazon doesn’t actually come out and call it “hug of death” prevention but they should.
- It’s very fast. Likely much faster at serving a file over the Internet than a server you’ve set up.
Core S3 Concepts
Bucket of Bits
If you’ve dabbled at all with S3 you’ve almost immediately come across the term “bucket” - which is generally described as a kind of top level folder under your S3 AWS account.
And, while that’s true, it’s much easier to get to grips with how to set things up if you consider each “bucket” as if it were a distinct file server.
Got an web app staging server? Then you probably need a staging bucket.
All of your users in New York? Then you should probably put your bucket in the datacenter closest to New York.
Similarly, much of the security and (very cool) features of S3 are set at the bucket level.

Pictured above: Artists interpretation of Werner Vogels checking S3 status.
Lies, Lies, Lies and Objects
So, here’s the thing. I’ve been saying “files” up until now and it’s really “objects” that are stored in S3. In my defense, even when you’re actually using S3 you and all the other developers will still say to each other: “Hey, did those files copy over to that bucket?“”
But S3 isn’t really a file system - and it’s a little hard to get your mind around the fact that it’s not.
Inside of a bucket it’s just a list of unique names (that typically look like filename paths) and then there are the actual bits (which are the objects we call files) stored on the whirring hard drives of AWS.
So when you’re looking at a file in a bucket with a name like:
/avatars/2015/01/22/aang.png
A folder structure of avatars > 2015 > 01 > 22 doesn’t actually exist. In truth it’s the same as if the file were called:
_avatars_2015_01_22_aang.png
Thankfully, in the same way that the human mind cannot grasp the infinite expanse of the cosmos, we’re all also incapable of handling more than a dozen files laying around without wanting to organize them in some way.
So, EVERY S3 client participates in the polite fiction that a forward slash means that Oh Boy! there’s a folder here, even when there’s really not one.
Where the Problems Start
First: Imagine you have 100 files in your avatar “folder” and you then rename that folder. If it were a normal file system that would be one operation and take a few milliseconds. With S3 it would be 100 separate painful steps as each and every file would have to be touched to rename it (you’re actually moving each file).
Second: The second big problem is that different S3 clients have developed different workarounds for the lack of true folders. So it’s quite common to see weird extra files that are storing information and for different clients to create issues with each other as they both vie for control.
What is S3 Used For?
Static Web Site Hosting
If you have site that is “static” (made up of HTML, images, css and js), S3 is a fantastic way to host it. Many FTP clients have added the ability to connect with S3, making it very easy to get going.
The process:
- Upload some files.
- Set their permissions to be viewable by anyone on the Internet.
- View the files in your web browser.
You can additionally add a custom domain and SSL certificate to your S3 hosted site.
Transmit's "FTP" S3 Config
S3 Clients
- Cyberduck - https://cyberduck.io
- Transmit - https://panic.com/transmit/
- AWS Web Client - https://aws.amazon.com
- S3 Browser - http://s3browser.com/
Storing Lots of User Generated Data
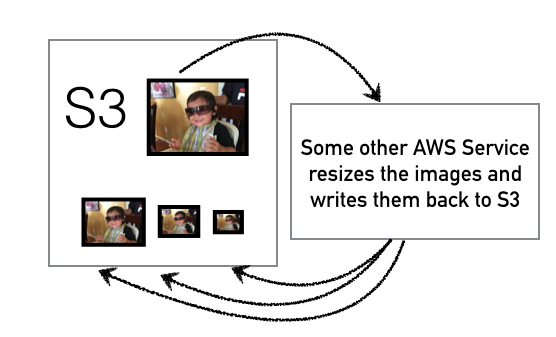
Nowadays, it is very common that web applications let users upload images for sharing or just to have a custom avatar.
At even a small scale this becomes a big storage issue. You’ll typically split the originally uploaded image up into a bunch of different sizes to handle different use cases.
Storing Image Variations
Data Analysis
You have a business that does lots of analysis of big text files (SEC filing documents, legal briefs or my unedited screenplay for Big Momma’s House 10). You’d first put these files onto S3 before pushing them around to other AWS services for analysis.
S3 is integrated enough that it will even kick off events for you. So when you upload your TPSReport-203043.txt, it can pass it off to another service to be processed.
Offsite Backups
If you’re hosting your apps internally or with a non AWS web host, copying over backups from there is a great way to reduce your overall risk.
How to Get Started
If you’d like to play around with the basics of S3 and get a feel for what it can do, I’d recommend the AWS tutorial on Setting up a Static Website. While simple, you’ll touch at least briefly on most of the AWS features.
Official Docs: http://docs.aws.amazon.com/AmazonS3/latest/dev/HostingWebsiteOnS3Setup.html